Scenario: A package with a Data Flow task runs multiple times and
inserts duplicate records in the destination table.The destination table is a
transactional table with Numeric Identity column for transaction_id for each
record inserted.Although the records are duplicate,they are still unique
because of the identity property of the transaction_id column.
Following would be the best way to
delete the duplicate records while maintaining the identity of the first load
inserted.
The package loads data in
destination table TBL_Transaction_Details as below.

After the package execution the data
in the table looks like:
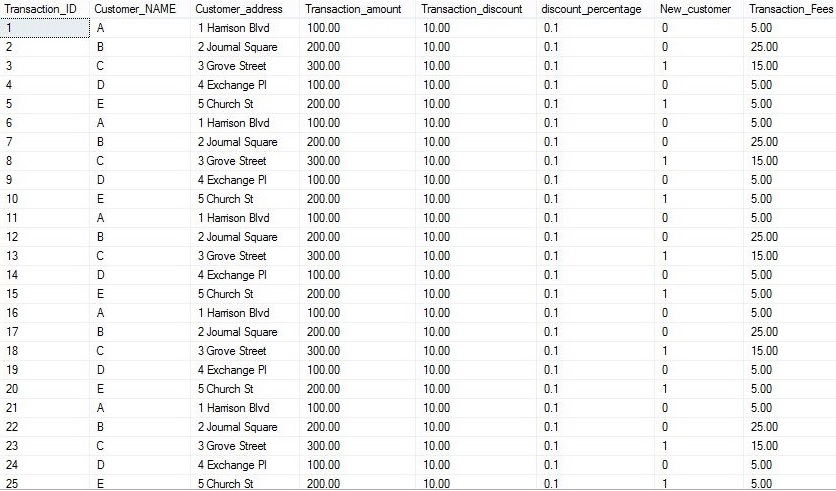
The Data from Transaction_Id 6 onwards is
duplicate which needs to be deleted.
Using a CTE code with rownumber over partition by the duplicated column values and order by the transaction id, will
remove the duplicate transactions while restoring the id's of the first load.
WITH CTE_Transaction_Details
([Customer_NAME]
,[Customer_address]
,[Transaction_amount]
,[Transaction_discount]
,[discount_percentage]
,[New_customer]
,[Transaction_Fees],Count_duplicate)
AS
(
SELECT [Customer_NAME]
,[Customer_address]
,[Transaction_amount]
,[Transaction_discount]
,[discount_percentage]
,[New_customer]
,[Transaction_Fees]
,ROW_NUMBER() OVER(PARTITION BY [Customer_NAME]
,[Customer_address]
,[Transaction_amount]
,[Transaction_discount]
,[discount_percentage]
,[New_customer]
,[Transaction_Fees] ORDER BY transaction_id) AS Count_duplicate
FROM
[dbo].[TBL_Transaction_Details]
)
DELETE
FROM CTE_Transaction_Details
WHERE count_duplicate > 1
GO
When we delete from a CTE it deletes
from the source table
After the above code is executed the
table is cleaned of the duplicate data













































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}